
2.1 Understanding Hyperspectral Data
Hyperspectral imaging produces large, information-rich datasets that require proper structuring, calibration, and preprocessing for accurate analysis. In this module, we break down the structure of hyperspectral data, the essential correction steps applied to it, and key preprocessing techniques that transform raw data into actionable insights.

What is a Hypercube?
A hyperspectral data cube, also known as a hypercube, is a three-dimensional array of data representing:
- X, Y – the spatial dimensions (rows and columns of an image)
- ℷ – the spectral dimension, consisting of hundreds of narrow, contiguous wavelength bands
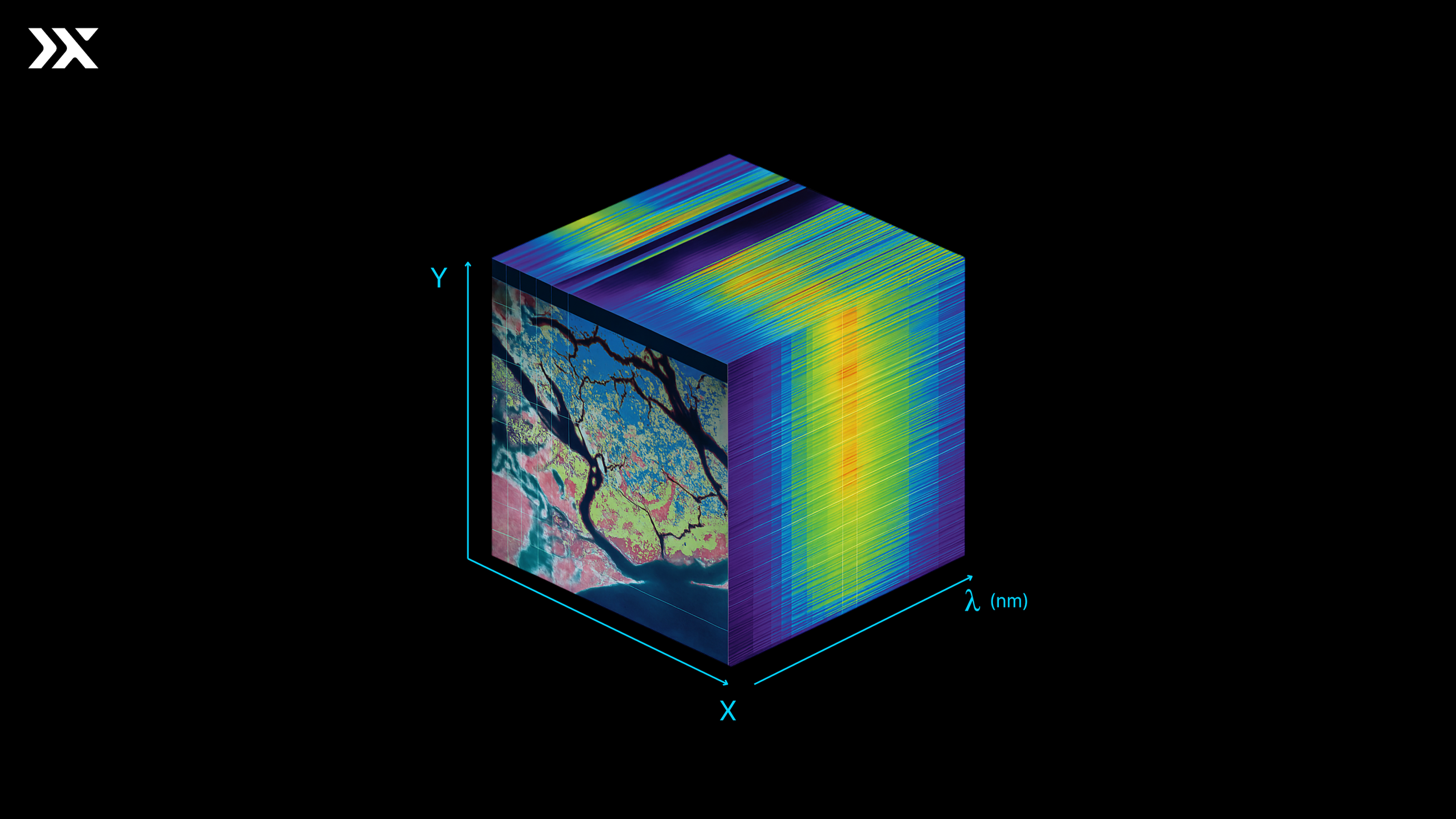
Each pixel in a hyperspectral image holds a complete spectral signature, enabling fine-grained material identification across a scene. Instead of a single colour value, a pixel in a hypercube contains a vector of reflectance values corresponding to the wavelengths captured by the sensor.
This structure supports both spatial and spectral analysis, answering questions about not only where something is but also what it’s made of.
Common file formats & metadata
Hyperspectral data is typically stored in formats that support multiple spectral layers and associated metadata.
Metadata in Hyperspectral Data
Metadata provides essential contextual information required for interpretation and processing. It often includes:
- Wavelengths and spectral bandwidths (centre wavelength, FWHM)
- Acquisition parameters (date, time, solar angle, viewing geometry)
- Sensor/platform information
- Radiometric calibration coefficients
- Spatial reference system and geolocation details
- Atmospheric model settings (if corrected)
Metadata is typically stored in .hdr files, sidecar XMLs, or embedded in formats like HDF5.
No items found.